So optimieren Sie einen Matmul CUDA-Kern für CuBLAS-ähnliche Leistung: Ein Arbeitsprotokoll
31. Dezember 2022
In diesem Artikel werde ich eine in CUDA geschriebene Implementierung der Matrixmultiplikation iterativ optimieren. Mein Ziel ist es nicht, einen Ersatz für cuBLAS zu bauen, sondern die wichtigsten Leistungsmerkmale von GPUs, die für modernes Deep Learning verwendet werden, tiefgehend zu verstehen. Dazu gehören unter anderem das Zusammenführen globaler Speicherzugriffe, Shared Memory Caching und Belegungsoptimierungen. Sie können den Code für alle Kernel von Github herunterladen. Schauen Sie sich auch das Repository von Wangzyon an, das ich als Ausgangspunkt für meine Neufassung verwendet habe. Dieser Beitrag ist weniger ausgefeilt als meine normalen Uploads und enthält viel mehr Randnotizen. Ich habe es als Notizblock für Ideen und Kritzeleien beim Schreiben der Kerne verwendet. Deshalb habe ich es ein Arbeitstagebuch genannt :)
Die Matrixmultiplikation auf GPUs ist derzeit vielleicht der wichtigste existierende Algorithmus, da er fast jeden FLOP beim Training und Ableiten großer Deep-Learning-Modelle ausmacht . Wie viel Arbeit ist also erforderlich, um ein leistungsstarkes CUDA-SGEMMSGEMM zu schreiben, das C = αAB + βC mit einfacher Genauigkeit (= 32b) ausführt? von Null? Ich beginne mit einem naiven Kernel und wende Schritt-für-Schritt-Optimierungen an, bis wir weniger als 80 % Leistung von cuBLAS (NVIDIAs offizieller Matrixbibliothek) erreichen: cuBLAS bei FP32, das heißt. In meinem Kontext ermöglicht das Ausführen des Matmul mit TF32- oder BF16-Präzision cuBLAS, die Tensorkerne zu verwenden, was FLOPS um das 2,5-fache oder 3,5-fache erhöht. Ich werde mir vielleicht in einem zukünftigen Artikel Tensorkerne / Warp-Matrix-Funktionen ansehen.
Kern GFLOP Performance im Vergleich zu cuBLAS (fp32) 1: Naiv 309 1,3 % 2: GMEM-Koaleszenz 2006 8,2 % 3: SMEM-Blockierung 2984 12,2 % 4: 1D-Kachel 8626 35,3 % 5: 2D-Kachel 16134 66,0 % 6: Lasten vektorisieren 20358 83,2 % 0: CUBLAS 24441 100,0 % Kern 1: Naive ImplementierungIm CUDA-Programmiermodell ist die Berechnung in einer dreistufigen Hierarchie geordnet. Jeder Aufruf eines CUDA-Cores erzeugt ein neues Grid, das aus mehreren Blöcken besteht. Jeder Block besteht aus bis zu 1024 einzelnen Threads. Diese Konstanten können im CUDA-Programmierhandbuch eingesehen werden. Threads, die sich im gleichen Block befinden, haben Zugriff auf die gleiche Shared Memory Region (SMEM).
Die Anzahl der Threads in einem Block kann mit einer Variablen konfiguriert werden, die normalerweise blockDim heißt und ein Vektor ist, der aus drei Ganzzahlen besteht. Die Einträge in diesem Vektor geben die Größen von blockDim.x, blockDim.y und blockDim.z an, wie unten gezeigt:
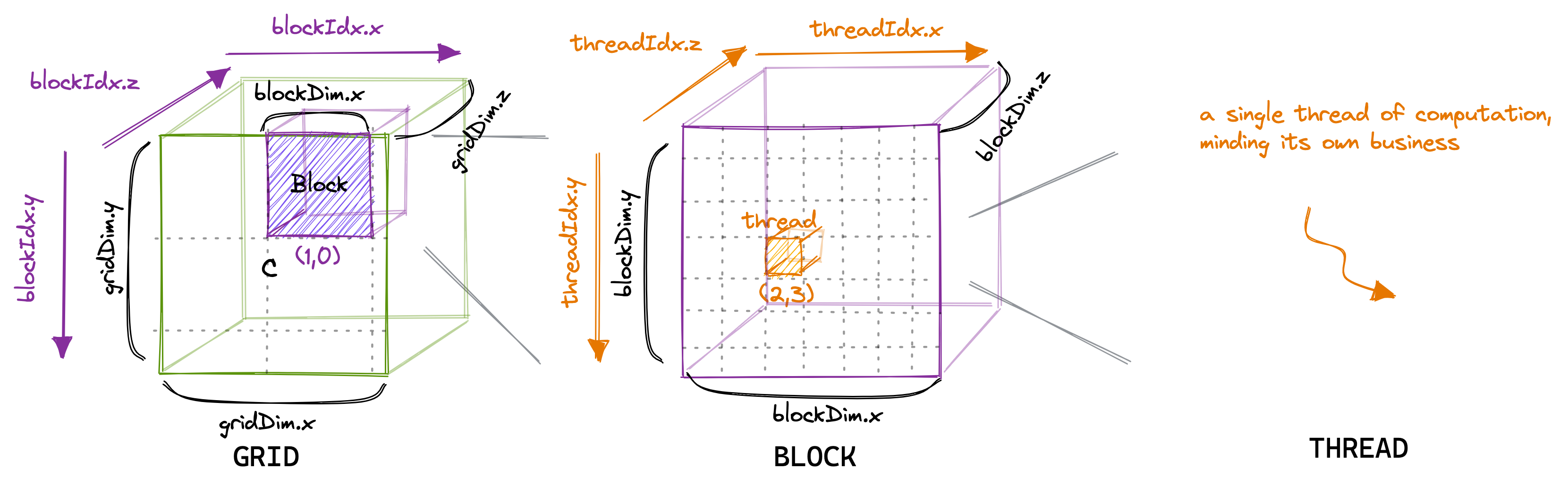
In ähnlicher Weise ist die Anzahl der Blöcke in einem Raster mithilfe der gridDim-Variablen konfigurierbar. Wenn wir einen neuen Kernel aus hostIn Accelerator-Jargon starten, bezieht sich host auf die CPU und device ist der Beschleuniger, hier die GPU, es erstellt ein einzelnes Raster, das die Blöcke und enthält Leitungen wie angegeben. Von nun an werde ich nur noch über 2D-Gitter und -Blöcke sprechen, zum Teil, weil 3D-Strukturen selten verwendet werden und das Zeichnen in 3D zu schwierig ist. Es ist wichtig, im Hinterkopf zu behalten, dass es bei der Thread-Hierarchie, die wir gerade besprochen haben, hauptsächlich um die Programmkorrektheit geht. Wie wir später sehen werden, ist es für die Programmleistung keine gute Idee, alle Threads im selben Block gleich zu behandeln.
Für unseren ersten Kern verwenden wir die Gitter-, Block- und Thread-Hierarchie, um jedem Thread einen eindeutigen Eintrag in der Ergebnismatrix C zuzuweisen. Dann berechnet dieser Thread das Skalarprodukt der entsprechenden Zeile von A und aus dem Spalte von B und schreiben das Ergebnis nach C. Da jeder Slot in C von einem einzelnen Thread geschrieben wird, müssen wir keine Synchronisation durchführen. Wir starten den Kernel wie folgt:
// Erstellen Sie so viele Blöcke wie nötig, um ganz C abzubilden dim3 gridDim (CEIL_DIV (M, 32), CEIL_DIV (N, 32), 1); // 32 * 32 = 1024 Threads pro Block dim3 block D...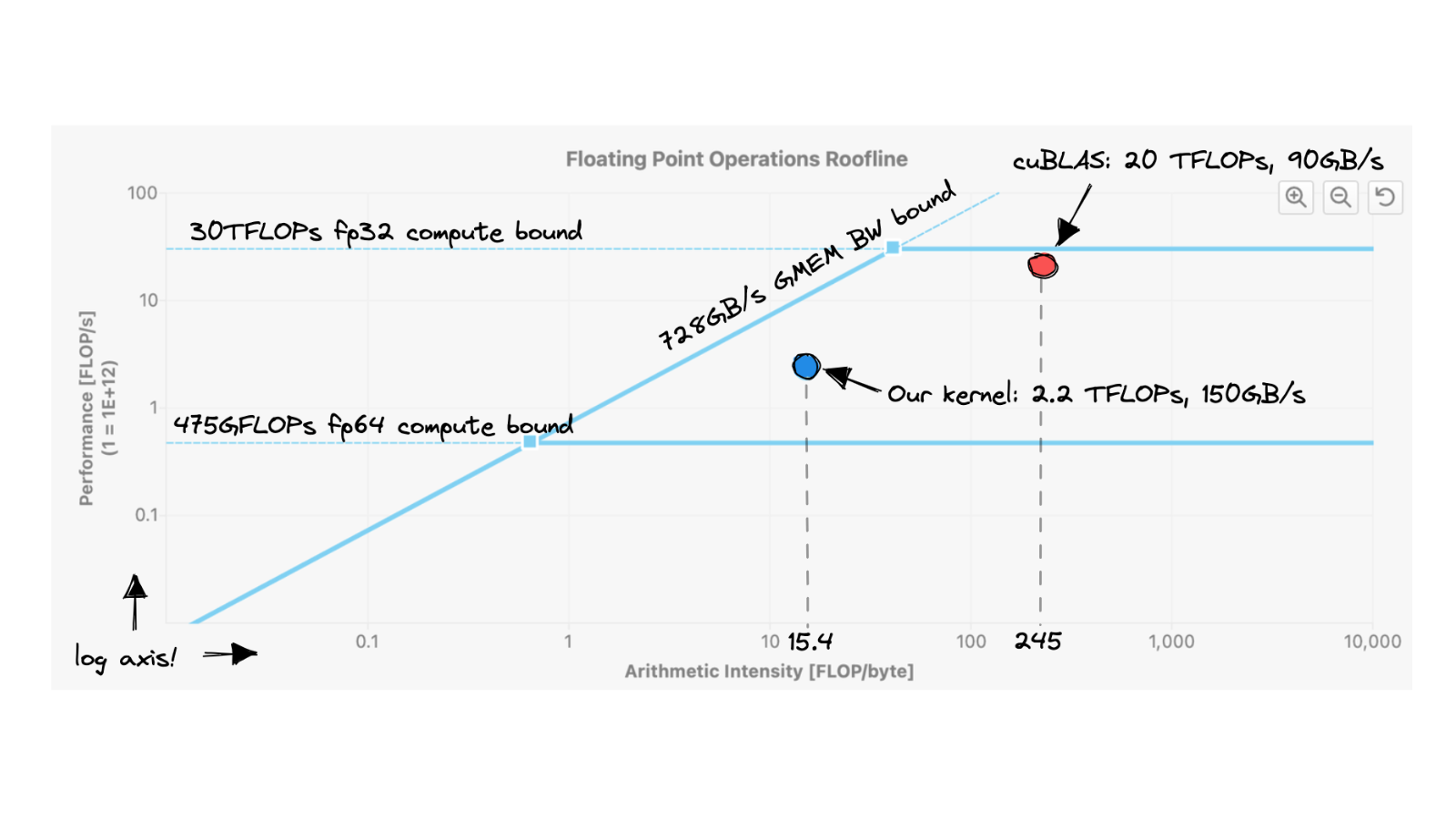
31. Dezember 2022
In diesem Artikel werde ich eine in CUDA geschriebene Implementierung der Matrixmultiplikation iterativ optimieren. Mein Ziel ist es nicht, einen Ersatz für cuBLAS zu bauen, sondern die wichtigsten Leistungsmerkmale von GPUs, die für modernes Deep Learning verwendet werden, tiefgehend zu verstehen. Dazu gehören unter anderem das Zusammenführen globaler Speicherzugriffe, Shared Memory Caching und Belegungsoptimierungen. Sie können den Code für alle Kernel von Github herunterladen. Schauen Sie sich auch das Repository von Wangzyon an, das ich als Ausgangspunkt für meine Neufassung verwendet habe. Dieser Beitrag ist weniger ausgefeilt als meine normalen Uploads und enthält viel mehr Randnotizen. Ich habe es als Notizblock für Ideen und Kritzeleien beim Schreiben der Kerne verwendet. Deshalb habe ich es ein Arbeitstagebuch genannt :)
Die Matrixmultiplikation auf GPUs ist derzeit vielleicht der wichtigste existierende Algorithmus, da er fast jeden FLOP beim Training und Ableiten großer Deep-Learning-Modelle ausmacht . Wie viel Arbeit ist also erforderlich, um ein leistungsstarkes CUDA-SGEMMSGEMM zu schreiben, das C = αAB + βC mit einfacher Genauigkeit (= 32b) ausführt? von Null? Ich beginne mit einem naiven Kernel und wende Schritt-für-Schritt-Optimierungen an, bis wir weniger als 80 % Leistung von cuBLAS (NVIDIAs offizieller Matrixbibliothek) erreichen: cuBLAS bei FP32, das heißt. In meinem Kontext ermöglicht das Ausführen des Matmul mit TF32- oder BF16-Präzision cuBLAS, die Tensorkerne zu verwenden, was FLOPS um das 2,5-fache oder 3,5-fache erhöht. Ich werde mir vielleicht in einem zukünftigen Artikel Tensorkerne / Warp-Matrix-Funktionen ansehen.
Kern GFLOP Performance im Vergleich zu cuBLAS (fp32) 1: Naiv 309 1,3 % 2: GMEM-Koaleszenz 2006 8,2 % 3: SMEM-Blockierung 2984 12,2 % 4: 1D-Kachel 8626 35,3 % 5: 2D-Kachel 16134 66,0 % 6: Lasten vektorisieren 20358 83,2 % 0: CUBLAS 24441 100,0 % Kern 1: Naive ImplementierungIm CUDA-Programmiermodell ist die Berechnung in einer dreistufigen Hierarchie geordnet. Jeder Aufruf eines CUDA-Cores erzeugt ein neues Grid, das aus mehreren Blöcken besteht. Jeder Block besteht aus bis zu 1024 einzelnen Threads. Diese Konstanten können im CUDA-Programmierhandbuch eingesehen werden. Threads, die sich im gleichen Block befinden, haben Zugriff auf die gleiche Shared Memory Region (SMEM).
Die Anzahl der Threads in einem Block kann mit einer Variablen konfiguriert werden, die normalerweise blockDim heißt und ein Vektor ist, der aus drei Ganzzahlen besteht. Die Einträge in diesem Vektor geben die Größen von blockDim.x, blockDim.y und blockDim.z an, wie unten gezeigt:
In ähnlicher Weise ist die Anzahl der Blöcke in einem Raster mithilfe der gridDim-Variablen konfigurierbar. Wenn wir einen neuen Kernel aus hostIn Accelerator-Jargon starten, bezieht sich host auf die CPU und device ist der Beschleuniger, hier die GPU, es erstellt ein einzelnes Raster, das die Blöcke und enthält Leitungen wie angegeben. Von nun an werde ich nur noch über 2D-Gitter und -Blöcke sprechen, zum Teil, weil 3D-Strukturen selten verwendet werden und das Zeichnen in 3D zu schwierig ist. Es ist wichtig, im Hinterkopf zu behalten, dass es bei der Thread-Hierarchie, die wir gerade besprochen haben, hauptsächlich um die Programmkorrektheit geht. Wie wir später sehen werden, ist es für die Programmleistung keine gute Idee, alle Threads im selben Block gleich zu behandeln.
Für unseren ersten Kern verwenden wir die Gitter-, Block- und Thread-Hierarchie, um jedem Thread einen eindeutigen Eintrag in der Ergebnismatrix C zuzuweisen. Dann berechnet dieser Thread das Skalarprodukt der entsprechenden Zeile von A und aus dem Spalte von B und schreiben das Ergebnis nach C. Da jeder Slot in C von einem einzelnen Thread geschrieben wird, müssen wir keine Synchronisation durchführen. Wir starten den Kernel wie folgt:
// Erstellen Sie so viele Blöcke wie nötig, um ganz C abzubilden dim3 gridDim (CEIL_DIV (M, 32), CEIL_DIV (N, 32), 1); // 32 * 32 = 1024 Threads pro Block dim3 block D...What's Your Reaction?



















