Maschinelles Lernen, Fazit: Haben „No-Code“-Tools die manuelle Analyse geschlagen?
Maschinelles Lernen, Fazit: Haben „No-Code“-Tools die manuelle Analyse geschlagen?
Erweitern
Aurich Lawson | Getty Images
Ich bin kein Datenwissenschaftler. Und obwohl ich mit einem Jupyter-Notebook vertraut bin und ziemlich viel Python-Code geschrieben habe, behaupte ich nicht, ein Experte für maschinelles Lernen zu sein. Als ich also den ersten Teil unseres No-Code/Low-Code-Experiments zum maschinellen Lernen durchführte und bei einem Modell eine Genauigkeit von über 90 % erzielte, vermutete ich, dass ich etwas falsch gemacht hatte.
Falls Sie nicht mitverfolgt haben, finden Sie hier einen kurzen Überblick, bevor wir zu den ersten beiden Artikeln dieser Reihe zurückkehren. Um zu sehen, wie weit maschinelle Lernwerkzeuge für den Rest von uns gekommen sind – und um mich von der nicht zu gewinnenden Aufgabe zu erlösen, die mir letztes Jahr mit maschinellem Lernen übertragen wurde – habe ich einen abgenutzten Herzinfarkt-Datensatz aus einem Archiv der University of California genommen. Irvine und versuchte, die Ergebnisse von Data-Science-Studenten mit dem „einfachen Knopf“ von Low-Code- und No-Code-Tools, dem Amazon Web Services-Code, zu übertreffen.
Der Sinn dieses Experiments war zu sehen:
Wenn ein relativer Anfänger diese Werkzeuge effektiv und genau verwenden kann
Wenn Werkzeuge rentabler wären, als jemanden zu finden, der weiß, was er tut, und es ihm zu geben
Das ist nicht gerade ein wahres Bild davon, wie Machine-Learning-Projekte normalerweise ablaufen. Und wie ich festgestellt habe, soll die von Amazon Web Services bereitgestellte „No-Code“-Option – SageMaker Canvas – Hand in Hand mit dem stärker auf Data Science ausgerichteten Ansatz von SageMaker Studio arbeiten. Aber Canvas übertraf das, was ich mit dem Low-Code-Ansatz von Studio erreichen konnte, aber wahrscheinlich wegen meiner weniger erfahrenen Hände in der Datenverwaltung.
(Für diejenigen, die die beiden vorherigen Artikel nicht gelesen haben, ist es jetzt an der Zeit, sie nachzuholen: hier ist Teil eins und hier ist Teil zwei.)
Bewertung der Roboterarbeit
Canvas ermöglichte mir, einen gemeinsam nutzbaren Link zu exportieren, der das Modell öffnete, das ich mit meiner Vollversion aus den über 590 Zeilen von Patientendaten der Cleveland Clinic und des ungarischen Instituts für Kardiologie erstellt hatte. Dieser Link gab mir einen etwas besseren Einblick in das, was in der sehr schwarzen Box von Canvas mit Studio passiert ist, einer Jupyter-basierten Plattform für datenwissenschaftliche Experimente und datenwissenschaftliches maschinelles Lernen.
Wie der Name schon sagt, basiert Jupyter auf Python. Es ist eine Webschnittstelle zu einer Containerumgebung, mit der Sie je nach Aufgabe Kernel basierend auf verschiedenen Python-Implementierungen hochfahren können.
Beispiele der verschiedenen in Studio verfügbaren Kernel-Container.
Die Cores können mit allen Modulen gefüllt werden, die das Projekt benötigt, wenn es codeorientierte Erkundungen durchführt, wie z. B. die Python Data Analysis Library (pandas) und SciKit-Learn (sklearn ). Ich habe eine lokale Version von Jupyter Lab verwendet, um den größten Teil meiner anfänglichen Datenanalyse durchzuführen, um AWS-Rechenzeit zu sparen.
Die mit dem Canvas-Link erstellte Studio-Umgebung enthielt vorgefertigte Inhalte, die eine Vorschau auf die erstellte Canvas-Vorlage geben, die ich im letzten Beitrag kurz besprochen habe:
Ich bin kein Datenwissenschaftler. Und obwohl ich mit einem Jupyter-Notebook vertraut bin und ziemlich viel Python-Code geschrieben habe, behaupte ich nicht, ein Experte für maschinelles Lernen zu sein. Als ich also den ersten Teil unseres No-Code/Low-Code-Experiments zum maschinellen Lernen durchführte und bei einem Modell eine Genauigkeit von über 90 % erzielte, vermutete ich, dass ich etwas falsch gemacht hatte.
Falls Sie nicht mitverfolgt haben, finden Sie hier einen kurzen Überblick, bevor wir zu den ersten beiden Artikeln dieser Reihe zurückkehren. Um zu sehen, wie weit maschinelle Lernwerkzeuge für den Rest von uns gekommen sind – und um mich von der nicht zu gewinnenden Aufgabe zu erlösen, die mir letztes Jahr mit maschinellem Lernen übertragen wurde – habe ich einen abgenutzten Herzinfarkt-Datensatz aus einem Archiv der University of California genommen. Irvine und versuchte, die Ergebnisse von Data-Science-Studenten mit dem „einfachen Knopf“ von Low-Code- und No-Code-Tools, dem Amazon Web Services-Code, zu übertreffen.
Der Sinn dieses Experiments war zu sehen:
Wenn ein relativer Anfänger diese Werkzeuge effektiv und genau verwenden kann
Wenn Werkzeuge rentabler wären, als jemanden zu finden, der weiß, was er tut, und es ihm zu geben
Das ist nicht gerade ein wahres Bild davon, wie Machine-Learning-Projekte normalerweise ablaufen. Und wie ich festgestellt habe, soll die von Amazon Web Services bereitgestellte „No-Code“-Option – SageMaker Canvas – Hand in Hand mit dem stärker auf Data Science ausgerichteten Ansatz von SageMaker Studio arbeiten. Aber Canvas übertraf das, was ich mit dem Low-Code-Ansatz von Studio erreichen konnte, aber wahrscheinlich wegen meiner weniger erfahrenen Hände in der Datenverwaltung.
(Für diejenigen, die die beiden vorherigen Artikel nicht gelesen haben, ist es jetzt an der Zeit, sie nachzuholen: hier ist Teil eins und hier ist Teil zwei.)
Bewertung der Roboterarbeit
Canvas ermöglichte mir, einen gemeinsam nutzbaren Link zu exportieren, der das Modell öffnete, das ich mit meiner Vollversion aus den über 590 Zeilen von Patientendaten der Cleveland Clinic und des ungarischen Instituts für Kardiologie erstellt hatte. Dieser Link gab mir einen etwas besseren Einblick in das, was in der sehr schwarzen Box von Canvas mit Studio passiert ist, einer Jupyter-basierten Plattform für datenwissenschaftliche Experimente und datenwissenschaftliches maschinelles Lernen.
Wie der Name schon sagt, basiert Jupyter auf Python. Es ist eine Webschnittstelle zu einer Containerumgebung, mit der Sie je nach Aufgabe Kernel basierend auf verschiedenen Python-Implementierungen hochfahren können.
Beispiele der verschiedenen in Studio verfügbaren Kernel-Container.
Die Cores können mit allen Modulen gefüllt werden, die das Projekt benötigt, wenn es codeorientierte Erkundungen durchführt, wie z. B. die Python Data Analysis Library (pandas) und SciKit-Learn (sklearn ). Ich habe eine lokale Version von Jupyter Lab verwendet, um den größten Teil meiner anfänglichen Datenanalyse durchzuführen, um AWS-Rechenzeit zu sparen.
Die mit dem Canvas-Link erstellte Studio-Umgebung enthielt vorgefertigte Inhalte, die eine Vorschau auf die erstellte Canvas-Vorlage geben, die ich im letzten Beitrag kurz besprochen habe:
 Erweitern
Aurich Lawson | Getty Images
Erweitern
Aurich Lawson | Getty Images
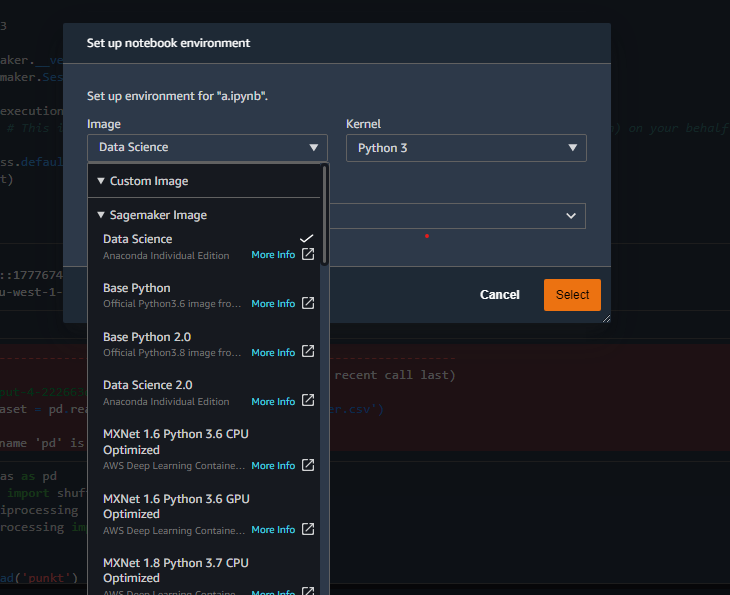 Beispiele der verschiedenen in Studio verfügbaren Kernel-Container.
Beispiele der verschiedenen in Studio verfügbaren Kernel-Container.