(Не) збільшуйте попередження до 11
Нещодавно сайт для розміщення коду GitHub широко розгорнув інструмент під назвою CodeQL із досить агресивними налаштуваннями. Він виконує статичний аналіз коду та намагається повідомити про проблеми. Я використовую термін «статичний аналіз» для позначення аналізу, який не виконує код. Статичний аналіз обмежений: він може ідентифікувати низку справжніх помилок, але також має тенденцію виловлювати хибні спрацьовування: шаблони коду, які він вважає помилками, але такими не є.
Нещодавно кілька інженерів Intel розробили код, щоб додати підтримку AVX-512 до бібліотеки, підтримувати яку я допомагаю. Ми отримали такі жахливі попередження:
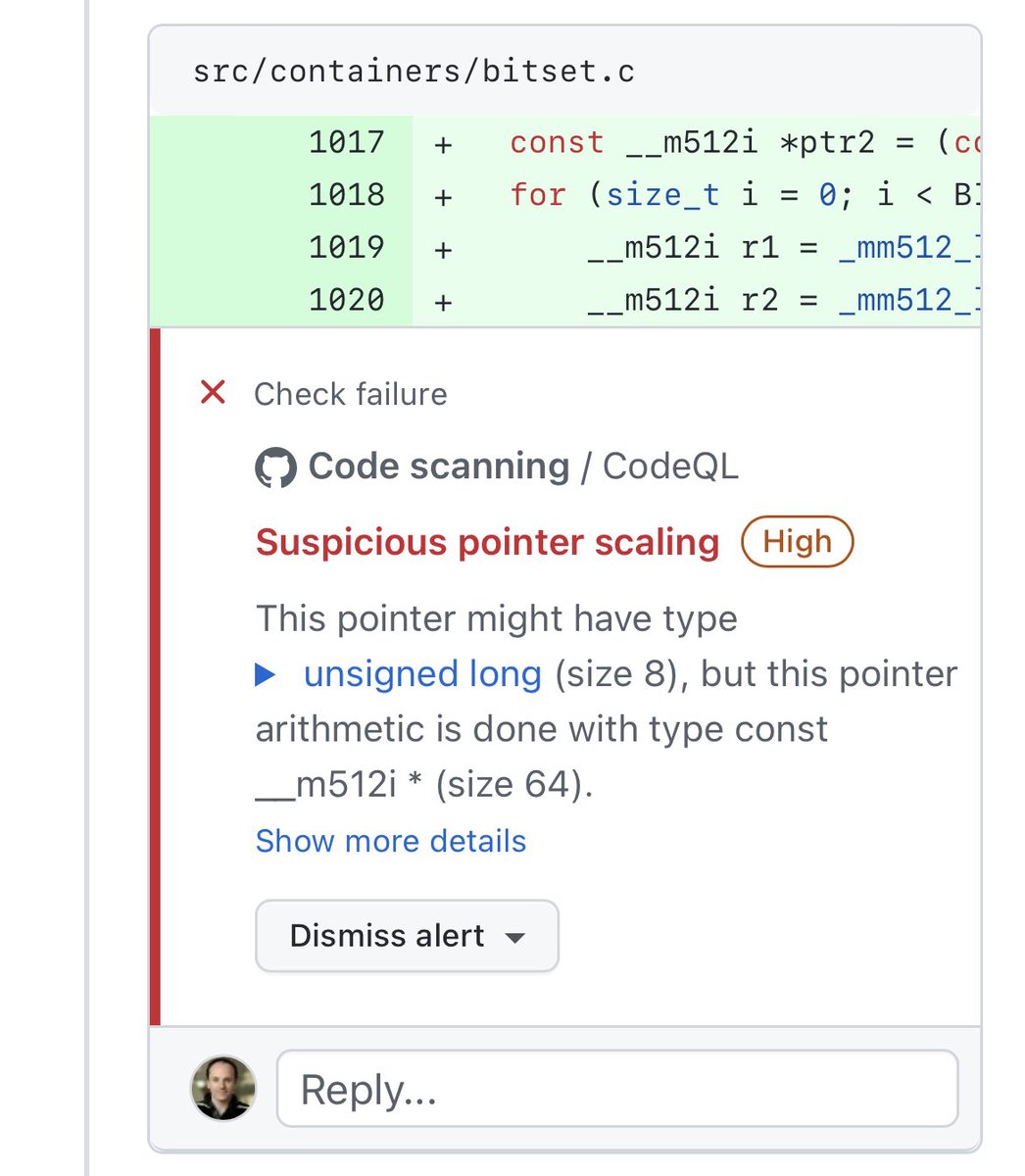
CodeQL скаржиться, що ми приймаємо в якості вхідних даних вказівник на 8-байтові слова та обробляємо його так, ніби це вказівник на 64-байтові слова. Якщо ви працюєте з AVX-512 і надаєте оптимізовані заміни існуючої функції, цей код є стандартним. І жоден відомий мені компілятор, навіть із найекстремальнішими налаштуваннями, ніколи не видасть попередження, не кажучи вже про страшну «Помилка перевірки високого ступеня серйозності».
Саме по собі це лише невелике роздратування, яке я можу ігнорувати. Однак я боюся, що це частина більшої тенденції, коли люди починають більше або більше покладатися на авторитетний статичний аналіз для оцінки якості коду. Чим більше попереджень, тим краще, вважають вони.
І справді, чим більше попереджень може згенерувати лінтер/перевірка, тим краще?
Ні. Це неправильно з кількох причин:
Попередження та хибні помилки можуть забрати значну кількість часу програміста. Ви можете сказати «ігноруйте їх», але навіть якщо ви це зробите, інші отримають такі ж попередження, і у них виникне спокуса або спробувати виправити ваш код, або повідомити про проблему вам. Таким чином, якщо не працювати виключно поодинці або в закритій групі, важко уникнути прірви часу. Навчання молодих програмістів уникати непроблем може зробити їх менш продуктивними. Дві найважливіші характеристики програмного забезпечення (по порядку): точність (якщо воно робить те, що ви кажете, що робить) і продуктивність (якщо воно ефективне). Виправлення поверхневих попереджень є легкою роботою, але часто це не сприяє коректності (тобто не виправляє помилки) чи прискоренню коду. Можливо, ви почуваєтеся продуктивно і вам може здаватися, що ви редагуєте багато коду, але що це для вас? Зміна коду для вирішення проблеми, яка не є проблемою, має відмінний від нуля шанс створити справжню помилку. Якщо у вас є код, який тривалий час працював у виробництві без помилок... спроба «виправити» його (якщо він не зламаний) може насправді його зламати. Ви повинні бути обережними, виправляючи код без вагомих доказів того, що існує справжня проблема. Ваша поведінка за замовчуванням має полягати в тому, щоб відмовлятися змінювати код, якщо ви не бачите переваги. Є винятки, але майже всі зміни коду повинні або виправити фактичну помилку, запровадити нову функцію або підвищити продуктивність. Під час програмування потрібно очистити свій ментальний простір. Відволікання - це погано. Вони роблять вас дурнішим. Таким чином, ваше середовище програмування не повинно мати непотрібних функцій.Давайте використаємо трохи математики. Припустімо, у моєму коді є помилки, і статичний засіб перевірки має певну ймовірність виявити помилку щоразу, коли видає попередження. З мого досвіду ця ймовірність може бути низькою...але точний відсоток не важливий для загальної картини. Дозвольте мені використати розумну модель. Враховуючи B помилок на 1000 рядків, ймовірність того, що моє попередження виявило помилку, відповідає логістичній функції, скажімо, 1/(1+exp(10 – B)). Отже, якщо я маю 10 помилок на 1000 рядків коду, то кожне попередження має 50% шансів бути корисним. Це досить оптимістично.
Відкликання – це кількість виявлених помилок. Якщо у моєму коді є 20 помилок на 1000 рядків, то наявність мільйона попереджень майже гарантує, що всі помилки будуть виявлені. Але людям потрібно буде багато працювати.
З огляду на B, скільки попереджень я маю зробити? Звичайно, у реальному світі я не знаю B і не знаю, чи корисність попереджень залежить від логістичної функції, але будь ласка.
Розумною відповіддю є те, що ми хочемо максимізувати показник F: середнє гармонійне між точністю та пам’яттю.
Я поспішно закодував модель на Python, де змінюю кількість попереджень. Нагадування завжди включає...

Нещодавно сайт для розміщення коду GitHub широко розгорнув інструмент під назвою CodeQL із досить агресивними налаштуваннями. Він виконує статичний аналіз коду та намагається повідомити про проблеми. Я використовую термін «статичний аналіз» для позначення аналізу, який не виконує код. Статичний аналіз обмежений: він може ідентифікувати низку справжніх помилок, але також має тенденцію виловлювати хибні спрацьовування: шаблони коду, які він вважає помилками, але такими не є.
Нещодавно кілька інженерів Intel розробили код, щоб додати підтримку AVX-512 до бібліотеки, підтримувати яку я допомагаю. Ми отримали такі жахливі попередження:
CodeQL скаржиться, що ми приймаємо в якості вхідних даних вказівник на 8-байтові слова та обробляємо його так, ніби це вказівник на 64-байтові слова. Якщо ви працюєте з AVX-512 і надаєте оптимізовані заміни існуючої функції, цей код є стандартним. І жоден відомий мені компілятор, навіть із найекстремальнішими налаштуваннями, ніколи не видасть попередження, не кажучи вже про страшну «Помилка перевірки високого ступеня серйозності».
Саме по собі це лише невелике роздратування, яке я можу ігнорувати. Однак я боюся, що це частина більшої тенденції, коли люди починають більше або більше покладатися на авторитетний статичний аналіз для оцінки якості коду. Чим більше попереджень, тим краще, вважають вони.
І справді, чим більше попереджень може згенерувати лінтер/перевірка, тим краще?
Ні. Це неправильно з кількох причин:
Попередження та хибні помилки можуть забрати значну кількість часу програміста. Ви можете сказати «ігноруйте їх», але навіть якщо ви це зробите, інші отримають такі ж попередження, і у них виникне спокуса або спробувати виправити ваш код, або повідомити про проблему вам. Таким чином, якщо не працювати виключно поодинці або в закритій групі, важко уникнути прірви часу. Навчання молодих програмістів уникати непроблем може зробити їх менш продуктивними. Дві найважливіші характеристики програмного забезпечення (по порядку): точність (якщо воно робить те, що ви кажете, що робить) і продуктивність (якщо воно ефективне). Виправлення поверхневих попереджень є легкою роботою, але часто це не сприяє коректності (тобто не виправляє помилки) чи прискоренню коду. Можливо, ви почуваєтеся продуктивно і вам може здаватися, що ви редагуєте багато коду, але що це для вас? Зміна коду для вирішення проблеми, яка не є проблемою, має відмінний від нуля шанс створити справжню помилку. Якщо у вас є код, який тривалий час працював у виробництві без помилок... спроба «виправити» його (якщо він не зламаний) може насправді його зламати. Ви повинні бути обережними, виправляючи код без вагомих доказів того, що існує справжня проблема. Ваша поведінка за замовчуванням має полягати в тому, щоб відмовлятися змінювати код, якщо ви не бачите переваги. Є винятки, але майже всі зміни коду повинні або виправити фактичну помилку, запровадити нову функцію або підвищити продуктивність. Під час програмування потрібно очистити свій ментальний простір. Відволікання - це погано. Вони роблять вас дурнішим. Таким чином, ваше середовище програмування не повинно мати непотрібних функцій.Давайте використаємо трохи математики. Припустімо, у моєму коді є помилки, і статичний засіб перевірки має певну ймовірність виявити помилку щоразу, коли видає попередження. З мого досвіду ця ймовірність може бути низькою...але точний відсоток не важливий для загальної картини. Дозвольте мені використати розумну модель. Враховуючи B помилок на 1000 рядків, ймовірність того, що моє попередження виявило помилку, відповідає логістичній функції, скажімо, 1/(1+exp(10 – B)). Отже, якщо я маю 10 помилок на 1000 рядків коду, то кожне попередження має 50% шансів бути корисним. Це досить оптимістично.
Відкликання – це кількість виявлених помилок. Якщо у моєму коді є 20 помилок на 1000 рядків, то наявність мільйона попереджень майже гарантує, що всі помилки будуть виявлені. Але людям потрібно буде багато працювати.
З огляду на B, скільки попереджень я маю зробити? Звичайно, у реальному світі я не знаю B і не знаю, чи корисність попереджень залежить від логістичної функції, але будь ласка.
Розумною відповіддю є те, що ми хочемо максимізувати показник F: середнє гармонійне між точністю та пам’яттю.
Я поспішно закодував модель на Python, де змінюю кількість попереджень. Нагадування завжди включає...
What's Your Reaction?






















