El modelo Muse de Google podría ser el próximo gran avance para la IA generativa
Consulte todas las sesiones bajo demanda de Smart Security Summit aquí.
2022 ha sido un gran año para la IA generativa, con el lanzamiento de modelos como DALL-E 2, Stable Diffusion, Imagen y Parti. Y 2023 parece encaminarse en esa dirección, ya que Google presentó su último modelo de síntesis de texto a imagen, Muse, a principios de este mes.
Al igual que otros modelos de texto a imagen, Muse es una red neuronal profunda que toma un mensaje de texto como entrada y genera una imagen que coincide con la descripción. Sin embargo, lo que diferencia a Muse de sus predecesores es su eficiencia y precisión. Al aprovechar la experiencia de trabajos anteriores en el campo y agregar nuevas técnicas, los investigadores de Google pudieron crear un modelo generativo que requiere menos recursos computacionales y avanza en algunos de los problemas que sufren otros modelos generativos.
Muse de Google utiliza la generación de imágenes basada en tokensMuse se basa en investigaciones anteriores sobre aprendizaje profundo, incluidos modelos de lenguaje extenso (LLM), redes generativas cuantificadas y transformadores de imágenes generativas ocultas.
"Un fuerte motivo fue nuestro interés en unificar la generación de imágenes y texto mediante el uso de tokens", dijo Dilip Krishnan, investigador de Google. "Muse se basa en ideas en MaskGit, una publicación anterior de nuestro grupo, y enmascara ideas de modelado de modelos de lenguaje grandes".
EventoCumbre de seguridad inteligente bajo demanda
Obtenga más información sobre el papel esencial de la IA y el ML en la ciberseguridad y los estudios de casos específicos de la industria. Mira las sesiones a pedido hoy.
mira aquíMuse aprovecha el condicionamiento en modelos de lenguaje previamente entrenados utilizados en trabajos anteriores, así como la idea de modelos en cascada, que toma prestada de Imagen. Una de las diferencias interesantes entre Muse y otros modelos similares es la generación de tokens discretos en lugar de representaciones a nivel de píxeles, lo que hace que la salida del modelo sea mucho más estable.
Al igual que otros generadores de texto a imagen, Muse está entrenado en un gran corpus de pares de subtítulos de imágenes. Un LLM preentrenado procesa la leyenda y genera una representación digital multidimensional integrada de la descripción textual. Al mismo tiempo, una cascada de dos codificadores-decodificadores de imágenes transforma diferentes resoluciones de la imagen de entrada en una matriz de tokens cuantificados.
Durante el entrenamiento, el modelo entrena un transformador base y un transformador de superresolución para alinear representaciones vectoriales sin costuras de texto con tokens de imagen y usarlos para representar la imagen. El modelo ajusta sus parámetros ocultando al azar tokens de imágenes e intentando predecirlos.
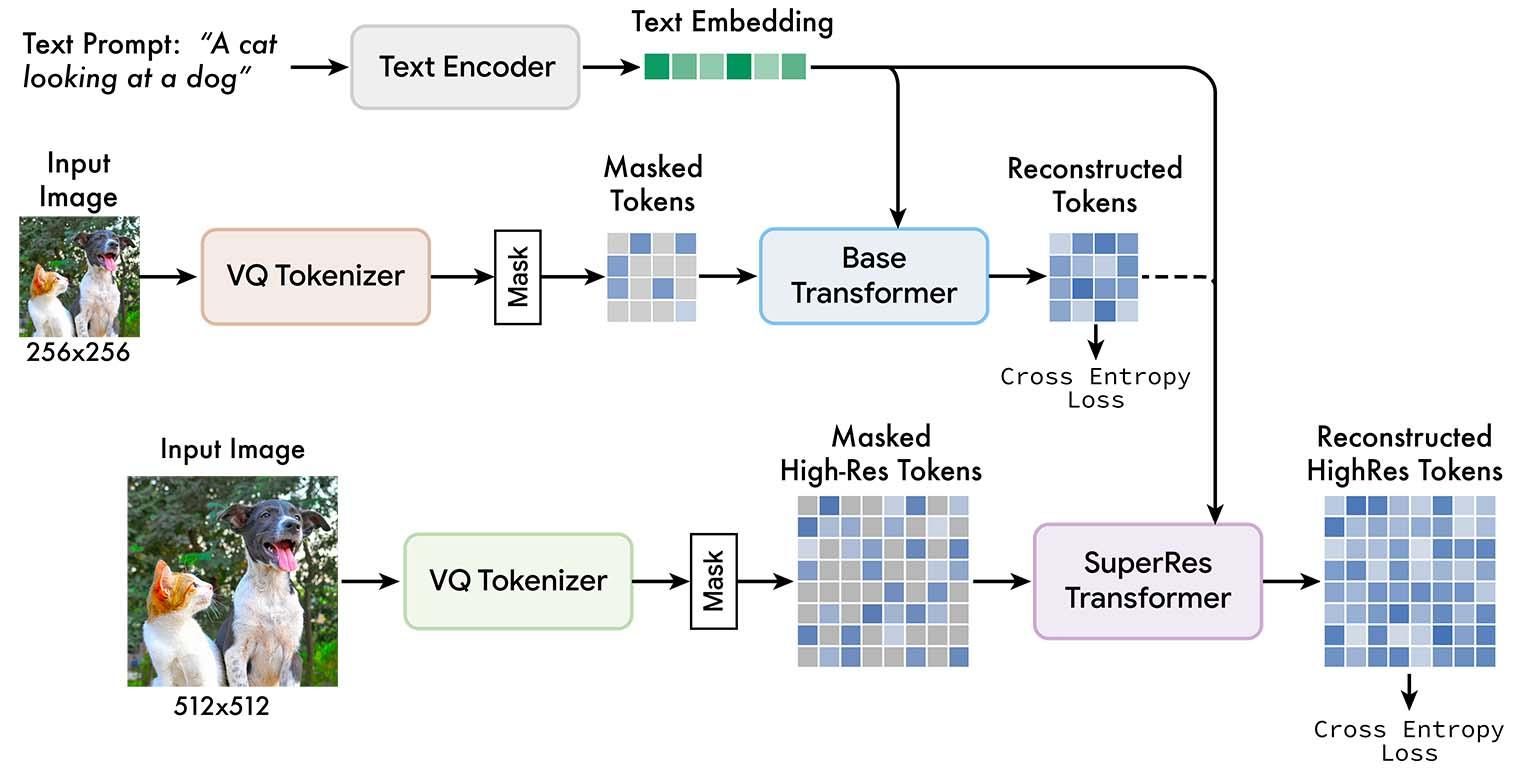
Una vez entrenado, el modelo puede generar tokens de imagen a partir de la incrustación de texto de un mensaje nuevo y usar tokens de imagen para crear nuevas imágenes de alta resolución.
Según Krishnan, una de las innovaciones de Muse es la decodificación paralela en el espacio simbólico, que es fundamentalmente diferente de los modelos autorregresivos y de difusión. Los modelos de difusión utilizan eliminación de ruido progresiva. Los modelos autorregresivos utilizan la decodificación en serie. La decodificación paralela en Muse proporciona una muy buena eficiencia sin pérdida de calidad visual.
"Consideramos Mu...

Consulte todas las sesiones bajo demanda de Smart Security Summit aquí.
2022 ha sido un gran año para la IA generativa, con el lanzamiento de modelos como DALL-E 2, Stable Diffusion, Imagen y Parti. Y 2023 parece encaminarse en esa dirección, ya que Google presentó su último modelo de síntesis de texto a imagen, Muse, a principios de este mes.
Al igual que otros modelos de texto a imagen, Muse es una red neuronal profunda que toma un mensaje de texto como entrada y genera una imagen que coincide con la descripción. Sin embargo, lo que diferencia a Muse de sus predecesores es su eficiencia y precisión. Al aprovechar la experiencia de trabajos anteriores en el campo y agregar nuevas técnicas, los investigadores de Google pudieron crear un modelo generativo que requiere menos recursos computacionales y avanza en algunos de los problemas que sufren otros modelos generativos.
Muse de Google utiliza la generación de imágenes basada en tokensMuse se basa en investigaciones anteriores sobre aprendizaje profundo, incluidos modelos de lenguaje extenso (LLM), redes generativas cuantificadas y transformadores de imágenes generativas ocultas.
"Un fuerte motivo fue nuestro interés en unificar la generación de imágenes y texto mediante el uso de tokens", dijo Dilip Krishnan, investigador de Google. "Muse se basa en ideas en MaskGit, una publicación anterior de nuestro grupo, y enmascara ideas de modelado de modelos de lenguaje grandes".
EventoCumbre de seguridad inteligente bajo demanda
Obtenga más información sobre el papel esencial de la IA y el ML en la ciberseguridad y los estudios de casos específicos de la industria. Mira las sesiones a pedido hoy.
mira aquíMuse aprovecha el condicionamiento en modelos de lenguaje previamente entrenados utilizados en trabajos anteriores, así como la idea de modelos en cascada, que toma prestada de Imagen. Una de las diferencias interesantes entre Muse y otros modelos similares es la generación de tokens discretos en lugar de representaciones a nivel de píxeles, lo que hace que la salida del modelo sea mucho más estable.
Al igual que otros generadores de texto a imagen, Muse está entrenado en un gran corpus de pares de subtítulos de imágenes. Un LLM preentrenado procesa la leyenda y genera una representación digital multidimensional integrada de la descripción textual. Al mismo tiempo, una cascada de dos codificadores-decodificadores de imágenes transforma diferentes resoluciones de la imagen de entrada en una matriz de tokens cuantificados.
Durante el entrenamiento, el modelo entrena un transformador base y un transformador de superresolución para alinear representaciones vectoriales sin costuras de texto con tokens de imagen y usarlos para representar la imagen. El modelo ajusta sus parámetros ocultando al azar tokens de imágenes e intentando predecirlos.
Una vez entrenado, el modelo puede generar tokens de imagen a partir de la incrustación de texto de un mensaje nuevo y usar tokens de imagen para crear nuevas imágenes de alta resolución.
Según Krishnan, una de las innovaciones de Muse es la decodificación paralela en el espacio simbólico, que es fundamentalmente diferente de los modelos autorregresivos y de difusión. Los modelos de difusión utilizan eliminación de ruido progresiva. Los modelos autorregresivos utilizan la decodificación en serie. La decodificación paralela en Muse proporciona una muy buena eficiencia sin pérdida de calidad visual.
"Consideramos Mu...
What's Your Reaction?




















