Scaling Mastodon facing the exodus
TL;DR: Mastodon's Sidekiq deferred execution tasks are the limiting factor for scaling federated traffic in a single-server or small-cluster deployment. Sidekiq performance scales poorly under a single process model and can be throttled by database performance in a deployment of the default Dockerized configuration.
If you're a struggling instance admin, go here.
I recently moved to a well-established Mastodon (Hometown fork) server called weirder.earth, a wonderful community with several very dedicated moderators and long-standing links to other respected servers in the Fediverse. All in all, it was lovely; the community is awesome, the Hometown fork has some nice easy to use features, and the moderators tend to weed out spam and bigotry pretty quickly.
Then Elon Musk bought Twitter.
The set upJust as tens of thousands of people fled Twitter to join the Fedivers, Weirder Earth had a pending storage migration. This didn't go well, for reasons unrelated to this post, and the instance was unavailable for several hours.
Normally this wouldn't be a problem; ActivityPub, the protocol that powers Mastodon and other fedivers software, is very resilient to failures, and most implementations have many built-in mechanisms like exponential backoff and so on to notify their neighbors when they come back online. This particular outage, however, coincided with a huge amount of traffic, so when the server came back online, there were several tens of thousands of messages waiting for it. Each of these messages requires a Sidekiq task that integrates it into the database, user timelines and notification lists, etc.
Sidekiq failed to handle this load.
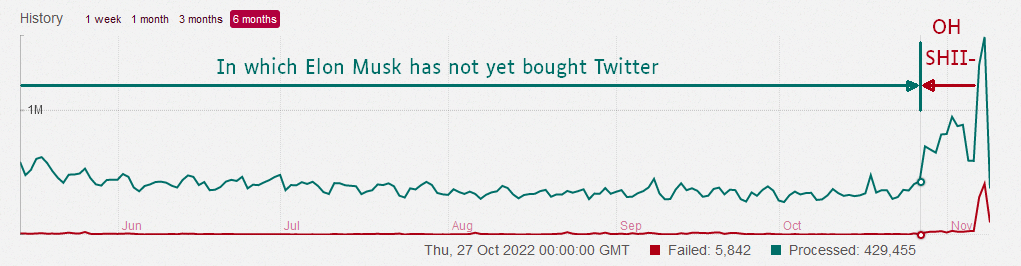 A screenshot of Weirder Earth Sidekiq dashboard screen, showing processed and failed tasks over time. Created and edited by Packbats.
A screenshot of Weirder Earth Sidekiq dashboard screen, showing processed and failed tasks over time. Created and edited by Packbats.Users began experiencing delays of several hours in inbound federation, although outbound federation was unaffected. For users of other instances, nothing was wrong; Posts from weirder.earth appeared within seconds, or around two minutes at worst. Even for weirder.earth users, the web interface worked perfectly fine; it's just that there was little new content to fill it.
The Sidekiq queue grew steadily over time, eventually peaking at over 200,000 queued jobs. In a conversation with the administrator of another instance of roughly similar size, I learned that processing a 6-figure number of tasks in a day is only a fairly recent phenomenon. So that was a problem.
The causeI was involved in this situation during the initial outage, helping troubleshoot Docker issues, alongside another user, the Packbats, and another instance admin. As Sidekiq's queue grew, myself and two of the instance admins looked into all the possible causes, mostly going through the documentation, since that wasn't an area of expertise for none of us.
It was immediately clear that at least part of the problem was Sidekiq's inability to successfully utilize the 8GB of memory and 4 CPU cores available on the server; the single Sidekiq process RSS was around 350MB, and the load factor averaged around 3 - not even fully utilizing the 4 available cores.
So we started increasing the number of workers available for Sidekiq. This was done by increasing MAX_THREADS and passing the -c ("concurrency") argument to Sidekiq. (We later learned that DB_POOL is more appropriate; see below.) We first increased to 15, then to 25, and finally to 50, which is Sidekiq's mythical "stable limit" according to several posts by StackOverflow.
That helped, but the queue depth kept growing, so we increased our database container's max connections to 200 (adding -c 'max_connections=200' to the 'invocation in docker-compose.yml) and increased to 150 Sidekiq threads. Again this helped, but overnight the queue continued to grow.
At this point, I realized the bottleneck was no longer in Sidekiq; individual tasks had gone from a few seconds to tens of seconds and sometimes even more than a minute. One of the instance administrators started PgHero and we realized that indeed, t...
TL;DR: Mastodon's Sidekiq deferred execution tasks are the limiting factor for scaling federated traffic in a single-server or small-cluster deployment. Sidekiq performance scales poorly under a single process model and can be throttled by database performance in a deployment of the default Dockerized configuration.
If you're a struggling instance admin, go here.
I recently moved to a well-established Mastodon (Hometown fork) server called weirder.earth, a wonderful community with several very dedicated moderators and long-standing links to other respected servers in the Fediverse. All in all, it was lovely; the community is awesome, the Hometown fork has some nice easy to use features, and the moderators tend to weed out spam and bigotry pretty quickly.
Then Elon Musk bought Twitter.
The set upJust as tens of thousands of people fled Twitter to join the Fedivers, Weirder Earth had a pending storage migration. This didn't go well, for reasons unrelated to this post, and the instance was unavailable for several hours.
Normally this wouldn't be a problem; ActivityPub, the protocol that powers Mastodon and other fedivers software, is very resilient to failures, and most implementations have many built-in mechanisms like exponential backoff and so on to notify their neighbors when they come back online. This particular outage, however, coincided with a huge amount of traffic, so when the server came back online, there were several tens of thousands of messages waiting for it. Each of these messages requires a Sidekiq task that integrates it into the database, user timelines and notification lists, etc.
Sidekiq failed to handle this load.
A screenshot of Weirder Earth Sidekiq dashboard screen, showing processed and failed tasks over time. Created and edited by Packbats.Users began experiencing delays of several hours in inbound federation, although outbound federation was unaffected. For users of other instances, nothing was wrong; Posts from weirder.earth appeared within seconds, or around two minutes at worst. Even for weirder.earth users, the web interface worked perfectly fine; it's just that there was little new content to fill it.
The Sidekiq queue grew steadily over time, eventually peaking at over 200,000 queued jobs. In a conversation with the administrator of another instance of roughly similar size, I learned that processing a 6-figure number of tasks in a day is only a fairly recent phenomenon. So that was a problem.
The causeI was involved in this situation during the initial outage, helping troubleshoot Docker issues, alongside another user, the Packbats, and another instance admin. As Sidekiq's queue grew, myself and two of the instance admins looked into all the possible causes, mostly going through the documentation, since that wasn't an area of expertise for none of us.
It was immediately clear that at least part of the problem was Sidekiq's inability to successfully utilize the 8GB of memory and 4 CPU cores available on the server; the single Sidekiq process RSS was around 350MB, and the load factor averaged around 3 - not even fully utilizing the 4 available cores.
So we started increasing the number of workers available for Sidekiq. This was done by increasing MAX_THREADS and passing the -c ("concurrency") argument to Sidekiq. (We later learned that DB_POOL is more appropriate; see below.) We first increased to 15, then to 25, and finally to 50, which is Sidekiq's mythical "stable limit" according to several posts by StackOverflow.
That helped, but the queue depth kept growing, so we increased our database container's max connections to 200 (adding -c 'max_connections=200' to the 'invocation in docker-compose.yml) and increased to 150 Sidekiq threads. Again this helped, but overnight the queue continued to grow.
At this point, I realized the bottleneck was no longer in Sidekiq; individual tasks had gone from a few seconds to tens of seconds and sometimes even more than a minute. One of the instance administrators started PgHero and we realized that indeed, t...
What's Your Reaction?





















