Як оптимізувати ядро Matmul CUDA для продуктивності, подібної до CuBLAS: робочий журнал
31 грудня 2022
У цій статті я буду ітеративно оптимізувати реалізацію множення матриць, написану в CUDA. Моя мета полягає не в створенні заміни cuBLAS, а в глибокому розумінні найважливіших характеристик продуктивності графічних процесорів, які використовуються для сучасного глибинного навчання. Це включає в себе об’єднання глобальних доступів до пам’яті, кешування спільної пам’яті та оптимізацію зайнятості, серед іншого. Ви можете завантажити код для всіх ядер з Github. Також перегляньте репозиторій wangzyon, який я використовував як відправну точку для свого переписування. Ця публікація менш відшліфована, ніж мої звичайні завантаження, і містить набагато більше додаткових приміток. Я використовував його як блокнот для ідей і дудлів під час написання основних. Тому я назвав його робочим щоденником :)
Матричне множення на графічних процесорах є, мабуть, найважливішим існуючим алгоритмом на даний момент, враховуючи, що він створює майже кожен FLOP під час навчання та виведення великих моделей глибокого навчання. Отже, скільки роботи потрібно, щоб написати добре продуктивний CUDA SGEMMSGEMM, який виконує C=αAB+βC з одиничною точністю (=32b). з нуля? Я почну з простого ядра та застосую покрокову оптимізацію, доки не досягнемо менше ніж 80% продуктивності cuBLAS (офіційної бібліотеки матриць NVIDIA): тобто cuBLAS на FP32. У моєму контексті виконання matmul із використанням точності TF32 або BF16 дозволяє cuBLAS використовувати тензорні ядра, що збільшує FLOPS у 2,5x або 3,5x. Я можу розглянути тензорні ядра/функції матриці викривлення в наступній статті.
Ядро GFLOP Продуктивність порівняно з cuBLAS (fp32) 1: Наївний 309 1,3% 2: Коалесценція GMEM 2006 рік 8,2% 3: Блокування SMEM 2984 12,2% 4: 1D плитка 8626 35,3% 5: Плитка 2D 16134 66,0% 6: Векторизація навантажень 20358 83,2% 0: КУБЛАС 24441 100,0% Ядро 1: Наївна реалізаціяУ моделі програмування CUDA обчислення впорядковуються за трирівневою ієрархією. Кожен виклик ядра CUDA створює нову сітку, що складається з кількох блоків. Кожен блок складається до 1024 окремих потоків. Ці константи можна переглянути в посібнику з програмування CUDA. Потоки, які знаходяться в одному блоці, мають доступ до однієї області спільної пам’яті (SMEM).
Кількість потоків у блоці можна налаштувати за допомогою змінної, яка зазвичай називається blockDim і є вектором, що складається з трьох цілих чисел. Записи в цьому векторі визначають розміри blockDim.x, blockDim.y і blockDim.z, як показано нижче:
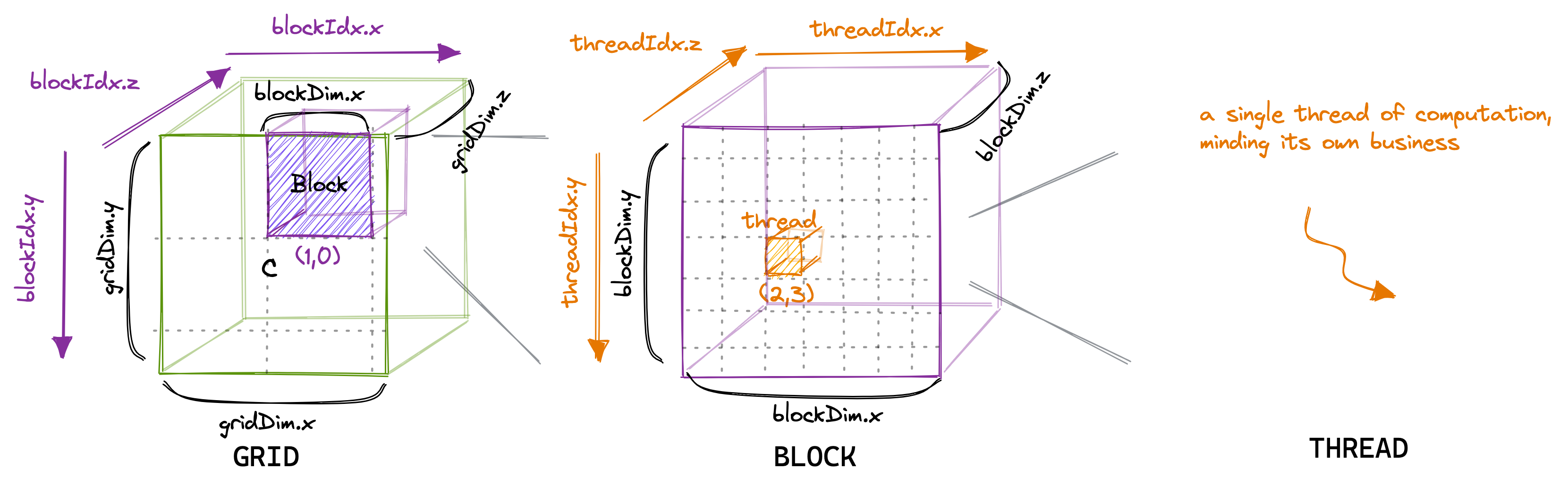
Так само кількість блоків у сітці можна налаштувати за допомогою змінної gridDim. Коли ми запускаємо нове ядро з прискорювача hostIn, host відноситься до ЦП, а device є прискорювачем, тут GPU, він створює єдину сітку, що містить блоки та дроти, як зазначено. Відтепер я говоритиму лише про двовимірні сітки та блоки, частково тому, що 3D-структура використовується рідко, і тому що малювати у 3D надто складно. Важливо мати на увазі, що ієрархія потоків, яку ми щойно обговорювали, насамперед стосується коректності програми. Для продуктивності програми, як ми побачимо пізніше, не варто розглядати всі потоки в одному блоці як однакові.
Для нашого першого ядра ми використаємо ієрархію сітки, блоку та потоку, щоб призначити кожному потоку унікальний запис у матриці результатів C. Тоді цей потік обчислить скалярний добуток відповідного рядка A та з стовпець B і записати результат у C. Оскільки кожен слот у C записується одним потоком, нам не потрібно виконувати синхронізацію. Ми запустимо ядро наступним чином:
// створити стільки блоків, скільки потрібно для відображення всього C dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1); // 32 * 32 = 1024 потоки на блок dim3 блок D...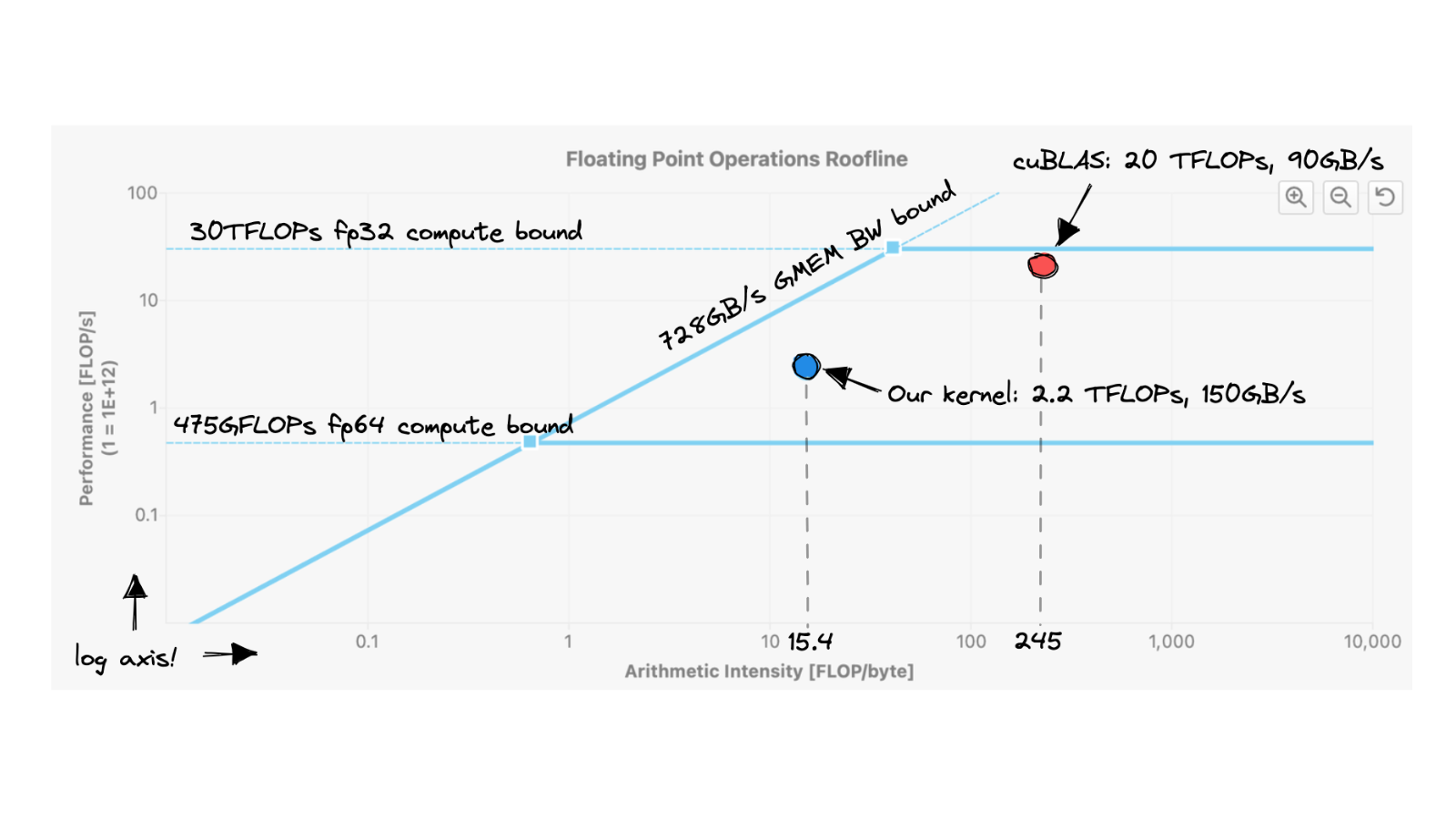
31 грудня 2022
У цій статті я буду ітеративно оптимізувати реалізацію множення матриць, написану в CUDA. Моя мета полягає не в створенні заміни cuBLAS, а в глибокому розумінні найважливіших характеристик продуктивності графічних процесорів, які використовуються для сучасного глибинного навчання. Це включає в себе об’єднання глобальних доступів до пам’яті, кешування спільної пам’яті та оптимізацію зайнятості, серед іншого. Ви можете завантажити код для всіх ядер з Github. Також перегляньте репозиторій wangzyon, який я використовував як відправну точку для свого переписування. Ця публікація менш відшліфована, ніж мої звичайні завантаження, і містить набагато більше додаткових приміток. Я використовував його як блокнот для ідей і дудлів під час написання основних. Тому я назвав його робочим щоденником :)
Матричне множення на графічних процесорах є, мабуть, найважливішим існуючим алгоритмом на даний момент, враховуючи, що він створює майже кожен FLOP під час навчання та виведення великих моделей глибокого навчання. Отже, скільки роботи потрібно, щоб написати добре продуктивний CUDA SGEMMSGEMM, який виконує C=αAB+βC з одиничною точністю (=32b). з нуля? Я почну з простого ядра та застосую покрокову оптимізацію, доки не досягнемо менше ніж 80% продуктивності cuBLAS (офіційної бібліотеки матриць NVIDIA): тобто cuBLAS на FP32. У моєму контексті виконання matmul із використанням точності TF32 або BF16 дозволяє cuBLAS використовувати тензорні ядра, що збільшує FLOPS у 2,5x або 3,5x. Я можу розглянути тензорні ядра/функції матриці викривлення в наступній статті.
Ядро GFLOP Продуктивність порівняно з cuBLAS (fp32) 1: Наївний 309 1,3% 2: Коалесценція GMEM 2006 рік 8,2% 3: Блокування SMEM 2984 12,2% 4: 1D плитка 8626 35,3% 5: Плитка 2D 16134 66,0% 6: Векторизація навантажень 20358 83,2% 0: КУБЛАС 24441 100,0% Ядро 1: Наївна реалізаціяУ моделі програмування CUDA обчислення впорядковуються за трирівневою ієрархією. Кожен виклик ядра CUDA створює нову сітку, що складається з кількох блоків. Кожен блок складається до 1024 окремих потоків. Ці константи можна переглянути в посібнику з програмування CUDA. Потоки, які знаходяться в одному блоці, мають доступ до однієї області спільної пам’яті (SMEM).
Кількість потоків у блоці можна налаштувати за допомогою змінної, яка зазвичай називається blockDim і є вектором, що складається з трьох цілих чисел. Записи в цьому векторі визначають розміри blockDim.x, blockDim.y і blockDim.z, як показано нижче:
Так само кількість блоків у сітці можна налаштувати за допомогою змінної gridDim. Коли ми запускаємо нове ядро з прискорювача hostIn, host відноситься до ЦП, а device є прискорювачем, тут GPU, він створює єдину сітку, що містить блоки та дроти, як зазначено. Відтепер я говоритиму лише про двовимірні сітки та блоки, частково тому, що 3D-структура використовується рідко, і тому що малювати у 3D надто складно. Важливо мати на увазі, що ієрархія потоків, яку ми щойно обговорювали, насамперед стосується коректності програми. Для продуктивності програми, як ми побачимо пізніше, не варто розглядати всі потоки в одному блоці як однакові.
Для нашого першого ядра ми використаємо ієрархію сітки, блоку та потоку, щоб призначити кожному потоку унікальний запис у матриці результатів C. Тоді цей потік обчислить скалярний добуток відповідного рядка A та з стовпець B і записати результат у C. Оскільки кожен слот у C записується одним потоком, нам не потрібно виконувати синхронізацію. Ми запустимо ядро наступним чином:
// створити стільки блоків, скільки потрібно для відображення всього C dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1); // 32 * 32 = 1024 потоки на блок dim3 блок D...What's Your Reaction?






















