Microsoft представляє модель штучного інтелекту, яка розуміє вміст зображення та вирішує візуальні головоломки
Microsoft представляє модель штучного інтелекту, яка розуміє вміст зображення та вирішує візуальні головоломки
Збільшити / Створене ШІ зображення електронного мозку з очним яблуком.
Арс-Техніка
У понеділок дослідники Microsoft представили Kosmos-1, мультимодальну модель, здатну аналізувати вміст зображень, розв’язувати візуальні головоломки, виконувати візуальне розпізнавання тексту, проходити візуальні тести IQ і розуміти інструкції природною мовою. Дослідники вважають, що мультимодальний ШІ, який об’єднує різні режими введення, як-от текст, аудіо, зображення та відео, є ключовим кроком до створення штучного загального інтелекту (AIG), здатного виконувати загальні завдання на рівні людини.
«Будучи фундаментальним елементом інтелекту, мультимодальне сприйняття є необхідністю для досягнення загального штучного інтелекту з точки зору отримання знань і закріплення в реальному світі», — пишуть дослідники у своїй науковій статті «Мова — це не все, що вам потрібно». : узгодження сприйняття з мовними моделями."
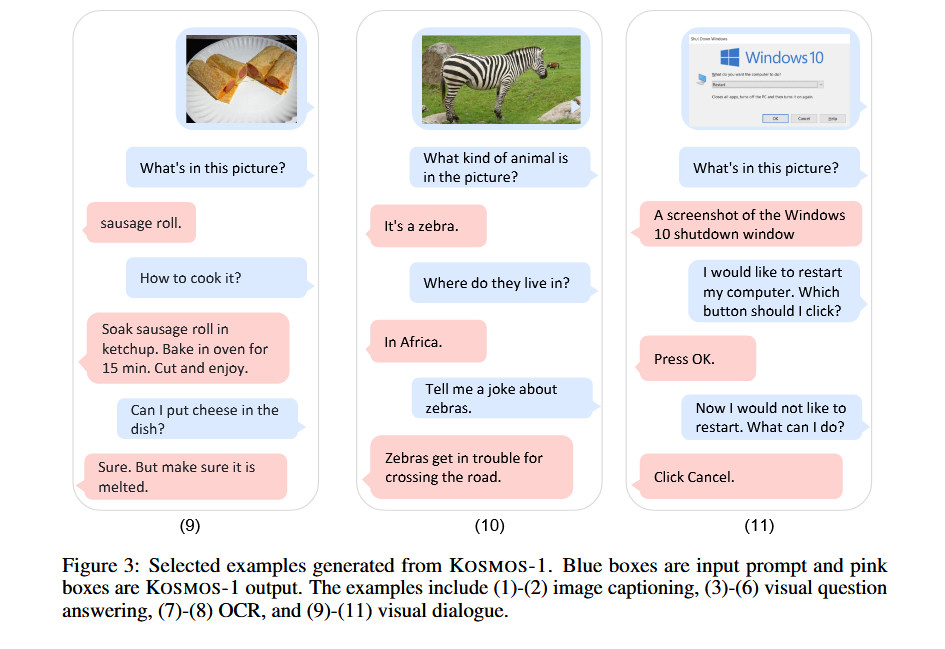
Візуальні приклади зі статті «Космос-1» показують, як модель аналізує зображення та відповідає на запитання про них, читає текст із зображення, пише підписи до зображень і виконує тест на візуальний IQ з точністю 22-26% (докладніше про це нижче). ).
Приклад, наданий Microsoft, коли Kosmos-1 відповідає на запитання про зображення та веб-сайти.
Microsoft
Наданий Microsoft приклад «Стимулювання мультимодального мисленнєвого ланцюга» для Космосу-1.
Microsoft
Приклад візуальної відповіді Космос-1 на запитання надано Microsoft.
Microsoft
Поки ЗМІ шумлять новинами про великі мовні моделі (LLM), деякі експерти зі штучного інтелекту вказують на мультимодальний штучний інтелект як на потенційний шлях до загального штучного інтелекту, гіпотетичної технології, яка, очевидно, зможе замінити людину в будь-якому інтелектуальному завданні ( і будь-які завдання). інтелектуальна праця). AGI є заявленою метою OpenAI, ключового бізнес-партнера Microsoft у сфері штучного інтелекту.
У цьому випадку Космос-1 виглядає чистим проектом Microsoft без участі OpenAI. Дослідники називають своє творіння «мультимодальною великою мовною моделлю» (MLLM), оскільки її коріння лежить у обробці природної мови, як-от текстовий LLM, такий як ChatGPT. І це показує: щоб Космос-1 приймав вхідні зображення, дослідники повинні спочатку перевести зображення в спеціальну серію токенів (по суті, текст), які може зрозуміти LLM. Стаття Космос-1 описує це більш детально:
Для формату введення ми зводимо вхідні дані як послідовність, прикрашену спеціальними маркерами. Зокрема, ми використовуємо і для позначення початку та кінця послідовності. Спеціальні маркери і вказують на початок і кінець вкладень закодованих зображень. Наприклад, «документ» — це текстовий запис, а «абзац, вбудовування зображення абзац» — це переплетене зображення та текст.
Збільшити / Створене ШІ зображення електронного мозку з очним яблуком.
Арс-Техніка
У понеділок дослідники Microsoft представили Kosmos-1, мультимодальну модель, здатну аналізувати вміст зображень, розв’язувати візуальні головоломки, виконувати візуальне розпізнавання тексту, проходити візуальні тести IQ і розуміти інструкції природною мовою. Дослідники вважають, що мультимодальний ШІ, який об’єднує різні режими введення, як-от текст, аудіо, зображення та відео, є ключовим кроком до створення штучного загального інтелекту (AIG), здатного виконувати загальні завдання на рівні людини.
«Будучи фундаментальним елементом інтелекту, мультимодальне сприйняття є необхідністю для досягнення загального штучного інтелекту з точки зору отримання знань і закріплення в реальному світі», — пишуть дослідники у своїй науковій статті «Мова — це не все, що вам потрібно». : узгодження сприйняття з мовними моделями."
Візуальні приклади зі статті «Космос-1» показують, як модель аналізує зображення та відповідає на запитання про них, читає текст із зображення, пише підписи до зображень і виконує тест на візуальний IQ з точністю 22-26% (докладніше про це нижче). ).
Приклад, наданий Microsoft, коли Kosmos-1 відповідає на запитання про зображення та веб-сайти.
Microsoft
Наданий Microsoft приклад «Стимулювання мультимодального мисленнєвого ланцюга» для Космосу-1.
Microsoft
Приклад візуальної відповіді Космос-1 на запитання надано Microsoft.
Microsoft
Поки ЗМІ шумлять новинами про великі мовні моделі (LLM), деякі експерти зі штучного інтелекту вказують на мультимодальний штучний інтелект як на потенційний шлях до загального штучного інтелекту, гіпотетичної технології, яка, очевидно, зможе замінити людину в будь-якому інтелектуальному завданні ( і будь-які завдання). інтелектуальна праця). AGI є заявленою метою OpenAI, ключового бізнес-партнера Microsoft у сфері штучного інтелекту.
У цьому випадку Космос-1 виглядає чистим проектом Microsoft без участі OpenAI. Дослідники називають своє творіння «мультимодальною великою мовною моделлю» (MLLM), оскільки її коріння лежить у обробці природної мови, як-от текстовий LLM, такий як ChatGPT. І це показує: щоб Космос-1 приймав вхідні зображення, дослідники повинні спочатку перевести зображення в спеціальну серію токенів (по суті, текст), які може зрозуміти LLM. Стаття Космос-1 описує це більш детально:
Для формату введення ми зводимо вхідні дані як послідовність, прикрашену спеціальними маркерами. Зокрема, ми використовуємо і для позначення початку та кінця послідовності. Спеціальні маркери і вказують на початок і кінець вкладень закодованих зображень. Наприклад, «документ» — це текстовий запис, а «абзац, вбудовування зображення абзац» — це переплетене зображення та текст.
 Збільшити / Створене ШІ зображення електронного мозку з очним яблуком.
Арс-Техніка
Збільшити / Створене ШІ зображення електронного мозку з очним яблуком.
Арс-Техніка