Новий штучний інтелект від Microsoft може імітувати будь-який голос за допомогою 3-секундного аудіо
Новий штучний інтелект від Microsoft може імітувати будь-який голос за допомогою 3-секундного аудіо
Збільшити / Створене штучним інтелектом зображення силуету людини.
Арс-Техніка
У четвер дослідники Microsoft анонсували нову модель штучного інтелекту для перетворення мовлення в текст під назвою VALL-E, яка може точно імітувати голос людини, коли їй надається трисекундний аудіосигнал. Вивчивши певний голос, VALL-E може синтезувати аудіо того, що людина говорить будь-що, і робити це таким чином, щоб зберегти емоційний тон мовця.
Його творці вважають, що VALL-E можна використовувати для високоякісних програм перетворення тексту в мовлення, редагування мовлення, де запис людини можна редагувати та модифікувати з транскрипції тексту (щоб зробити так, щоб він говорив те, що спочатку t) і створення аудіовмісту в поєднанні з іншими генеративними моделями ШІ, такими як GPT-3.
Microsoft називає VALL-E «моделлю мови нейронних кодеків», і вона базується на технології під назвою EnCodec, яку Meta анонсувала в жовтні 2022 року. На відміну від інших методів перетворення мови в текст, які зазвичай синтезують мову шляхом маніпулювання сигналами, VALL -E генерує дискретні аудіокодеки з текстових і акустичних підказок. По суті, він аналізує звук людини, розбиває цю інформацію на окремі компоненти (так звані «токени») за допомогою EnCodec і використовує навчальні дані, щоб узгодити те, що він «знає» про те, як звучатиме цей голос, якщо вона вимовила будь-які інші речення, окрім трисекундний зразок. Або, як повідомляє Microsoft у статті VALL-E:
Щоб синтезувати спеціальне мовлення (наприклад, нульовий TTS), VALL-E генерує відповідні акустичні маркери на основі акустичних маркерів 3-секундного запису та підказки фонеми, які відповідно обмежують мовця та інформацію про вміст. Зрештою, згенеровані акустичні маркери використовуються для синтезу остаточної форми хвилі за допомогою відповідного декодера нейронних кодеків.
Microsoft навчила можливості синтезу мовлення VALL-E на аудіотеці, зібраній Meta, під назвою LibriLight. Він містить 60 000 годин англійської мови від понад 7 000 носіїв, в основному взятих із загальнодоступних аудіокниг LibriVox. Щоб VALL-E генерував хороший результат, голос у трисекундному зразку має точно відповідати голосу в даних навчання.
На веб-сайті зразків VALL-E Microsoft надає десятки зразків аудіо моделі ШІ в дії. Зі зразків «Підказка динаміка» — це трисекундний звук, наданий VALL-E, який він повинен імітувати. «Основна правда» — це вже існуючий запис того самого оратора, який говорить певну фразу для порівняння (подібно до «контролю» в експерименті). «Базова лінія» є прикладом синтезу, який забезпечується звичайним методом синтезу тексту в мовлення, а зразок «VALL-E» є результатом моделі VALL-E.
Збільшити / Блок-схема VALL-E, надана дослідниками Microsoft.
Microsoft
Використовуючи VALL-E для отримання цих результатів, дослідники ввели лише трисекундний зразок «Підказка мовця» та текстовий рядок (те, що вони хотіли сказати голосом) у VALL-E. Тож порівняйте зразок "Ground Truth" із зразком "VALL-E". У деяких випадках два зразки дуже близькі. Деякі результати VALL-E здаються комп’ютерними, але інші потенційно можна прийняти за людську мову, що є метою моделі.
Збільшити / Створене штучним інтелектом зображення силуету людини.
Арс-Техніка
У четвер дослідники Microsoft анонсували нову модель штучного інтелекту для перетворення мовлення в текст під назвою VALL-E, яка може точно імітувати голос людини, коли їй надається трисекундний аудіосигнал. Вивчивши певний голос, VALL-E може синтезувати аудіо того, що людина говорить будь-що, і робити це таким чином, щоб зберегти емоційний тон мовця.
Його творці вважають, що VALL-E можна використовувати для високоякісних програм перетворення тексту в мовлення, редагування мовлення, де запис людини можна редагувати та модифікувати з транскрипції тексту (щоб зробити так, щоб він говорив те, що спочатку t) і створення аудіовмісту в поєднанні з іншими генеративними моделями ШІ, такими як GPT-3.
Microsoft називає VALL-E «моделлю мови нейронних кодеків», і вона базується на технології під назвою EnCodec, яку Meta анонсувала в жовтні 2022 року. На відміну від інших методів перетворення мови в текст, які зазвичай синтезують мову шляхом маніпулювання сигналами, VALL -E генерує дискретні аудіокодеки з текстових і акустичних підказок. По суті, він аналізує звук людини, розбиває цю інформацію на окремі компоненти (так звані «токени») за допомогою EnCodec і використовує навчальні дані, щоб узгодити те, що він «знає» про те, як звучатиме цей голос, якщо вона вимовила будь-які інші речення, окрім трисекундний зразок. Або, як повідомляє Microsoft у статті VALL-E:
Щоб синтезувати спеціальне мовлення (наприклад, нульовий TTS), VALL-E генерує відповідні акустичні маркери на основі акустичних маркерів 3-секундного запису та підказки фонеми, які відповідно обмежують мовця та інформацію про вміст. Зрештою, згенеровані акустичні маркери використовуються для синтезу остаточної форми хвилі за допомогою відповідного декодера нейронних кодеків.
Microsoft навчила можливості синтезу мовлення VALL-E на аудіотеці, зібраній Meta, під назвою LibriLight. Він містить 60 000 годин англійської мови від понад 7 000 носіїв, в основному взятих із загальнодоступних аудіокниг LibriVox. Щоб VALL-E генерував хороший результат, голос у трисекундному зразку має точно відповідати голосу в даних навчання.
На веб-сайті зразків VALL-E Microsoft надає десятки зразків аудіо моделі ШІ в дії. Зі зразків «Підказка динаміка» — це трисекундний звук, наданий VALL-E, який він повинен імітувати. «Основна правда» — це вже існуючий запис того самого оратора, який говорить певну фразу для порівняння (подібно до «контролю» в експерименті). «Базова лінія» є прикладом синтезу, який забезпечується звичайним методом синтезу тексту в мовлення, а зразок «VALL-E» є результатом моделі VALL-E.
Збільшити / Блок-схема VALL-E, надана дослідниками Microsoft.
Microsoft
Використовуючи VALL-E для отримання цих результатів, дослідники ввели лише трисекундний зразок «Підказка мовця» та текстовий рядок (те, що вони хотіли сказати голосом) у VALL-E. Тож порівняйте зразок "Ground Truth" із зразком "VALL-E". У деяких випадках два зразки дуже близькі. Деякі результати VALL-E здаються комп’ютерними, але інші потенційно можна прийняти за людську мову, що є метою моделі.
 Збільшити / Створене штучним інтелектом зображення силуету людини.
Арс-Техніка
Збільшити / Створене штучним інтелектом зображення силуету людини.
Арс-Техніка
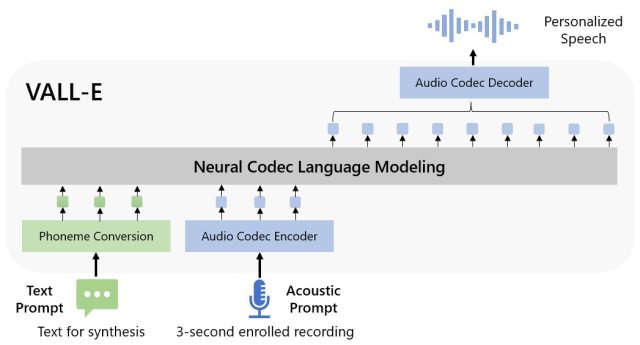 Збільшити / Блок-схема VALL-E, надана дослідниками Microsoft.
Microsoft
Збільшити / Блок-схема VALL-E, надана дослідниками Microsoft.
Microsoft